This is my mood (as identified from my facial expressions) over time while watching Never Mind the Buzzcocks.

The green areas are times where I looked happy.
This shows my mood while playing XBox Live. Badly.
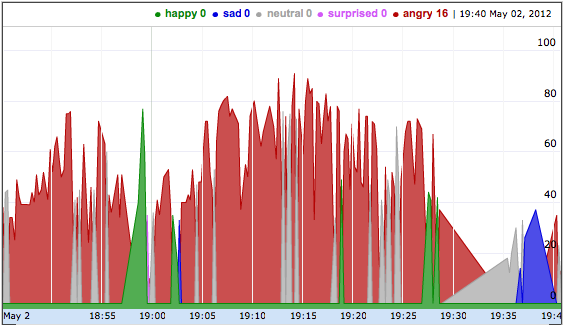
The red areas are times where I looked cross.
I smile more while watching comedies than when getting shot in the head. Shocker, eh?
A couple of years ago, I played with the idea of capturing my TV viewing habits and making some visualisations from them. This is a sort of return to that idea in a way.
A webcam lives on the top of our TV, mainly for skype calls. I was thinking that when watching TV, we’re often more or less looking at the webcam. What could it capture?
What about keeping track of how much I smile while watching a comedy, as a way of measuring which comedies I find funnier?

This suggests that, overall, I might’ve found Mock the Week funnier. But, this shows my facial expressions while watching Mock the Week.

It seems that, unlike with Buzzcocks, I really enjoyed the beginning bit, then perhaps got a bit less enthusiastic after a bit.
What about The Daily Show with Jon Stewart?

I think the two neutral bits are breaks for adverts.
Or classifying facial expressions by mood and looking for the dominant mood while watching something more serious on TV?
This shows my facial expressions while catching a bit of Newsnight.

On the whole, my expression remained reasonably neutral whilst watching the news, but you can see where I visibly reacted to a few of the news items.
Or looking to see how I react to playing different games on the XBox?
This shows my facial expressions while playing Modern Warfare 3 last night.

Mostly “sad”, as I kept getting shot in the head. With occasional moments where something made me smile or laugh, presumably when something went well.
Compare that with what I looked like while playing Blur (a car racing game).
It seems that I looked a little more aggressive while driving than running around getting shot. For last night, at any rate.
Not just about watching TV
I’m using face recognition to tell my expressions apart from other people in the room. This means there is also a bunch of stuff I could look into around how my expressions change based on who else is in the room, and their expressions?
For example, looking at how much of the time I spend smiling when I’m the only one in the room, compared with when one or both of my kids are in the room.

To be fair, this isn’t a scientific comparison. There are lots of factors here – for example, when the girls are in the room, I’ll probably be doing a different activity (such as playing a game with them or reading a story) to what I would be doing when by myself (typically doing some work on my laptop, or reading). This could be showing how much I smile based on which activity I’m doing. But I thought it was a cute result, anyway.
Limitations
This isn’t sophisticated stuff.
The webcam is an old, cheap one that only has a maximum resolution of 640×480, and I’m sat at the other end of the room to it. I can’t capture fine facial detail here.
I’m not doing anything complicated with video feeds. I’m just sampling by taking photos at regular intervals. You could reasonably argue that the funniest joke in the world isn’t going to get me to sustain a broad smile for over a minute, so there is a lot being missed here.
And my y-axis is a little suspect. I’m using the percentage level of confidence that the classifier had in identifying the mood. I’m doing this on the assumption that the more confident the classifier was, the stronger or more pronounced my facial expression probably was.
Regardless of all of this, I think the idea is kind of interesting.
How does it work?
The media server under the TV runs Ubuntu, so I had a lot of options. My language-of-choice for quick hacks is Python, so I used pygame to capture stills from the webcam.
For the complicated facial stuff, I’m using web services from face.com.
They have a REST API for uploading a photo to, getting back a blob of JSON with information about faces detected in the photo. This includes a guess at the gender, a description of mood from the facial expression, whether the face is smiling, and even an estimated age (often not complimentary!).
I used a Python client library from github to build the requests, so getting this working took no time at all.
There is a face recognition REST API. You can train the system to recognise certain faces. I didn’t write any code to do this, as I don’t need to do it again, so I did this using the API sandbox on the face.com website. I gave it a dozen or so photos with my face in, which seemed to be more than enough for the system to be able to tell me apart from someone else in the room.
My monitoring code puts what it measures about me in one log, and what it measures about anyone else in a second “guest log”.
This is the result of one evening’s playing, so I’ve not really finished with this. I think there is more to do with it, but for what it’s worth, this is what I’ve come up with so far.
The script
####################################################
# IMPORTS
####################################################
# imports for capturing a frame from the webcam
import pygame.camera
import pygame.image
# import for detecting faces in the photo
import face_client
# import for storing data
from pysqlite2 import dbapi2 as sqlite
# miscellaneous imports
from time import strftime, localtime, sleep
import os
import sys
####################################################
# CONSTANTS
####################################################
DB_FILE_PATH="/home/dale/dev/audiencemonitor/data/log.db"
FACE_COM_APIKEY="MY_API_KEY_HERE"
FACE_COM_APISECRET="MY_API_SECRET_HERE"
DALELANE_FACETAG="dalelane@dale.lane"
POLL_FREQUENCY_SECONDS=3
class AudienceMonitor():
#
# prepare the database where we store the results
#
def initialiseDB(self):
self.connection = sqlite.connect(DB_FILE_PATH, detect_types=sqlite.PARSE_DECLTYPES|sqlite.PARSE_COLNAMES)
cursor = self.connection.cursor()
cursor.execute('SELECT name FROM sqlite_master WHERE type="table" AND NAME="facelog" ORDER BY name')
if not cursor.fetchone():
cursor.execute('CREATE TABLE facelog(ts timestamp unique default current_timestamp, isSmiling boolean, smilingConfidence int, mood text, moodConfidence int)')
cursor.execute('SELECT name FROM sqlite_master WHERE type="table" AND NAME="guestlog" ORDER BY name')
if not cursor.fetchone():
cursor.execute('CREATE TABLE guestlog(ts timestamp unique default current_timestamp, isSmiling boolean, smilingConfidence int, mood text, moodConfidence int, agemin int, ageminConfidence int, agemax int, agemaxConfidence int, ageest int, ageestConfidence int, gender text, genderConfidence int)')
self.connection.commit()
#
# initialise the camera
#
def prepareCamera(self):
# prepare the webcam
pygame.camera.init()
self.camera = pygame.camera.Camera(pygame.camera.list_cameras()[0], (900, 675))
self.camera.start()
#
# take a single frame and store in the path provided
#
def captureFrame(self, filepath):
# save the picture
image = self.camera.get_image()
pygame.image.save(image, filepath)
#
# gets a string representing the current time to the nearest second
#
def getTimestampString(self):
return strftime("%Y%m%d%H%M%S", localtime())
#
# get attribute from face detection response
#
def getFaceDetectionAttributeValue(self, face, attribute):
value = None
if attribute in face['attributes']:
value = face['attributes'][attribute]['value']
return value
#
# get confidence from face detection response
#
def getFaceDetectionAttributeConfidence(self, face, attribute):
confidence = None
if attribute in face['attributes']:
confidence = face['attributes'][attribute]['confidence']
return confidence
#
# detects faces in the photo at the specified path, and returns info
#
def faceDetection(self, photopath):
client = face_client.FaceClient(FACE_COM_APIKEY, FACE_COM_APISECRET)
response = client.faces_recognize(DALELANE_FACETAG, file_name=photopath)
faces = response['photos'][0]['tags']
for face in faces:
userid = ""
faceuseridinfo = face['uids']
if len(faceuseridinfo) > 0:
userid = faceuseridinfo[0]['uid']
if userid == DALELANE_FACETAG:
smiling = self.getFaceDetectionAttributeValue(face, "smiling")
smilingConfidence = self.getFaceDetectionAttributeConfidence(face, "smiling")
mood = self.getFaceDetectionAttributeValue(face, "mood")
moodConfidence = self.getFaceDetectionAttributeConfidence(face, "mood")
self.storeResults(smiling, smilingConfidence, mood, moodConfidence)
else:
smiling = self.getFaceDetectionAttributeValue(face, "smiling")
smilingConfidence = self.getFaceDetectionAttributeConfidence(face, "smiling")
mood = self.getFaceDetectionAttributeValue(face, "mood")
moodConfidence = self.getFaceDetectionAttributeConfidence(face, "mood")
agemin = self.getFaceDetectionAttributeValue(face, "age_min")
ageminConfidence = self.getFaceDetectionAttributeConfidence(face, "age_min")
agemax = self.getFaceDetectionAttributeValue(face, "age_max")
agemaxConfidence = self.getFaceDetectionAttributeConfidence(face, "age_max")
ageest = self.getFaceDetectionAttributeValue(face, "age_est")
ageestConfidence = self.getFaceDetectionAttributeConfidence(face, "age_est")
gender = self.getFaceDetectionAttributeValue(face, "gender")
genderConfidence = self.getFaceDetectionAttributeConfidence(face, "gender")
# if the face wasnt recognisable, it might've been me after all, so ignore
if "tid" in face and face['recognizable'] == True:
self.storeGuestResults(smiling, smilingConfidence, mood, moodConfidence, agemin, ageminConfidence, agemax, agemaxConfidence, ageest, ageestConfidence, gender, genderConfidence)
print face['tid']
#
# stores face results in the DB
#
def storeGuestResults(self, smiling, smilingConfidence, mood, moodConfidence, agemin, ageminConfidence, agemax, agemaxConfidence, ageest, ageestConfidence, gender, genderConfidence):
cursor = self.connection.cursor()
cursor.execute('INSERT INTO guestlog(isSmiling, smilingConfidence, mood, moodConfidence, agemin, ageminConfidence, agemax, agemaxConfidence, ageest, ageestConfidence, gender, genderConfidence) values(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)',
(smiling, smilingConfidence, mood, moodConfidence, agemin, ageminConfidence, agemax, agemaxConfidence, ageest, ageestConfidence, gender, genderConfidence))
self.connection.commit()
#
# stores face results in the DB
#
def storeResults(self, smiling, smilingConfidence, mood, moodConfidence):
cursor = self.connection.cursor()
cursor.execute('INSERT INTO facelog(isSmiling, smilingConfidence, mood, moodConfidence) values(?, ?, ?, ?)',
(smiling, smilingConfidence, mood, moodConfidence))
self.connection.commit()
monitor = AudienceMonitor()
monitor.initialiseDB()
monitor.prepareCamera()
while True:
photopath = "data/photo" + monitor.getTimestampString() + ".bmp"
monitor.captureFrame(photopath)
try:
faceresults = monitor.faceDetection(photopath)
except:
print "Unexpected error:", sys.exc_info()[0]
os.remove(photopath)
sleep(POLL_FREQUENCY_SECONDS)












 On Wednesday,
On Wednesday,