A simple hands-on activity to let kids train a machine learning classifier to be able to play Rock, Paper, Scissors.
I’ve written and spoken before that I think we should do more to introduce children to the idea of machine learning. And I’ve tried introducing my two kids to it, such as by making a Code Club-style game with them: we built a system to play Guess Who, that they trained both to understand what you say and to recognise the characteristics of faces from photos.
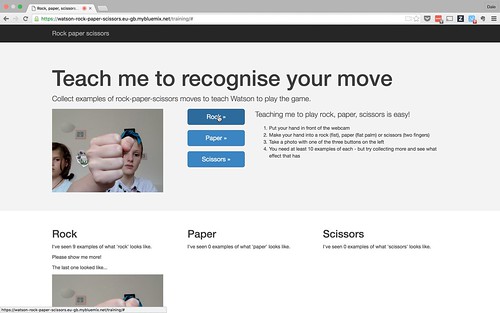
This weekend, we tried out another idea – Rock, Paper, Scissors from a web app, using the web cam to see your moves, and training a system to recognise your hand signs.

In many ways, this was simpler than the Guess Who project, and one I would’ve tried before if we’d thought of it! I’ve made getting the system to choose it’s next move very simple, as it just chooses one of the three options at random.
The machine learning element comes from the fact that I got them to train a custom image classifier to recognise what a ‘rock’, ‘paper’ and ‘scissors’ hand sign looks like.

Last night I hacked together a quick single-page training web app for them to use. Unlike with the Guess Who game, where we worked on it together to come up with the project, this time I made it myself to see how they’d get on with using it. (I was thinking that if it went well, I’d try using it with one of my school groups).
They got off to a good start… although I hadn’t counted on how much time Grace would spend checking out her hair once she saw the web cam video. 
Video of the kids getting started
I’ve got it so that you can take photos from the web cam by clicking on a button, and put the photo into one of three training groups – one each for rock, paper and scissors.

My hope was that the three hand signs – a fist, a flat palm, and two fingers – are distinct enough that an image classifier could quickly start to distinguish between them.
Although I should probably add some overlay to the live video to suggest where to put your hand, how close to the camera, etc. as their initial attempts were fairly inconsistent.
Video of their first attempt at training
As before, I’m using one of the Watson developer APIs available in Bluemix, called Visual Recognition.
To train it, you just need to upload zip files, where each zip file contains examples of photos of something you want to recognise.
In this case, we want to upload three zip files – one of photos of “rock”, one zip file of “paper” photos, one zip file of photos of “scissors”. And you can do all of that in a single HTTP POST, so the code behind the training app is very simple.

That said, I should still share the code.
It was hacked together in an evening, so it’s a complete mess. But I’ll try and find some spare time this week to tidy it up, and put the code somewhere in case it’s helpful. Some of the code for driving the webcam, zipping up the photos, and uploading them, might be useful to someone.
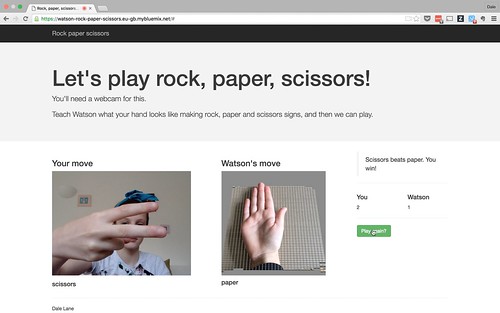
To test it, I made a simple game. I’ve got it keeping score to see how many moves you win against the random choices the game makes. Although Grace seemed more interested in counting the number of times the game correctly identified our moves. It wasn’t perfect!
(The “Watson’s move” images used in the game bit were made by Faith. She took photos of her own hand using an iPad, and did the weird grid background effect using PopAGraph. It wasn’t quite what I expected, but I think it looks kinda neat.)
As with the Guess Who activity, what most interested me was the girls’ reactions to the behaviour of the ML system. I was surprised that even after last time, their initial assumption was still that they could take one photo of each, and that would be enough. (Another reason why it’s worth doing a few of these activities to reinforce it).
But with a little nudging, they quickly saw how that the more examples they gave, the better the system performed.
Other than that, a lot of the lessons they learned were reminders of what we talked about before about what it’s like doing supervised learning projects.
The second attempt… another test after more training this time
One thing I was impressed with was when they thought that the training would be more effective if they used an actual rock, actual scissors, and a sheet of paper. Doing that made the accuracy a hundred times better. That makes sense, as they are much more distinct than all photos of hands, so that was a neat idea!
And that’s pretty much it. My second experiment at getting the kids to play with machine learning seemed to work pretty well.
I’ve put the app I made for them up on Bluemix so you’re welcome to give it a try it you like. It’s at https://watson-rock-paper-scissors.eu-gb.mybluemix.net.
You’ll have to get your own Visual Recognition API key to use it, though, but that supports a free trial, so hopefully that won’t put you off!
Third time lucky? Another test
Update 1:
A couple of friends pointed me at another recent IBM rock, paper, scissors project when I mentioned planning to do this.
It looks like a great project and is well worth a look – they’ve gone into using Apache Spark to create a system able look for patterns in how people play rock-paper-scissors and learn strategies to win the game.
More recently, they’ve even gotten a NAO robot to play the game for them!
I wasn’t aware of this work before, but decided to go ahead with our project anyway. Partly because my focus was different for this, but mostly because I think that the Agonies of Parallel Creation should never stop us from creating and sharing stuff. There’s no new idea under the sun, so if we wait for an idea that no-one has ever got close to, we’d stop creating anything.
That said, it’s a particularly surreal coincidence in this case, as this is not only an IBM project, but the author of that post is the great David Taieb who I used to work for when he worked on Watson! Small world.
Update 2:
Yes, I know you can see my API key in the video. But don’t worry. Bluemix makes it easy enough to revoke credentials so I’ve deleted that API key. Doing that was much quicker than learning enough video editing to be able to mask it out.

Feed footer idea nicked from 43 Folders using the FeedEntryHeader WordPress plugin.