STEMtech is a conference about the education of science, technology, engineering and maths. The attendees are an interesting mix of people from education and policy makers, as well as people like me from industry.
This year, they invited me to do a talk. My slides are shared but they’ll make no sense by themselves. What follows is roughly what I think I said.

Today I’m going to be talking about how we teach children to use computers. I’m not going to be talking about the current provision for this. I’m not going to be talking about what we necessarily need to be teaching children today, or maybe even tomorrow – partly because that’s already being well covered in the rest of the agenda today.
Instead, I’d like to use this session to think a little further ahead.
Big changes are coming in computing, and I think we should start thinking about how we’ll need to respond to them.

big trak. I loved this thing.
We used to have this at school when I was a kid, and I think I remember those lessons more strongly than any other lesson I did at school.

It had a keypad on the back. We’d program in a series of instructions – drive forwards this much, turn this much, fire the laser!
This was computing to me when I was young. This was robotics. This was cool.

Not all schools used big trak, but a lot of schools used something like this.
Variations of logo robot turtles have been widely used by many schools for many years, and are essentially the same thing – programming a series of instructions into a robot that follows them by driving around on the floor.

Fast forward to today, and I get to spend my Monday afternoons running a Code Club that I started in my local primary school: an after-school programming group. I get just an hour or two a week to see how kids learn about computers, what they think of them, how they approach them.

We use Scratch in Code Club, just as the school are now doing in lessons. It gives a visual, drag-and-drop way to build a sequence of instructions, which are followed by sprites moving around on the screen. This is how we explain programming and computers to children.
What strikes me doing this is how similar it is to what I was doing as a kid. It’s not exactly the same, but if you squint a bit and stand back a bit, it feels pretty similar. They’re both about showing children how to break an activity down into a series of steps.

And that’s to be expected. Programming itself is very similar today to what it was when I was at school. In some ways programming today is the same as it was five, ten, twenty years ago – it’s still about getting machines to perform tasks by getting people to define the sequence of instructions to follow. It’s only natural that this will be reflected in the way we introduce this to children.
But this is going to change.
We’re starting to see a future of computing that is going to be different, and we’re going to need new metaphors and new ways of introducing it and explaining it.

Computers have changed before.
We group the evolution of computers into eras, and they start in the 1800s in the era of tabulating machines.

I’m talking about systems like punched card machines.
Machines that could count more things, more quickly and more accurately than people possibly could.
Machines that were considered revolutionary because they enabled the US census in 1890 to be analysed before they needed to start the 1900 census.

Machines like the Hollerith tabulating machine were the computers of their day. This was the state of the art in technology.
Teaching computing then would’ve meant teaching about the capabilities of these machines. I don’t just mean the mechanics of feeding the cards into the machine, although that would’ve been part of it. I mean about looking at problems as collections of things that can be counted.

The era of tabulating machines was followed by the era of programmable machines, starting around about the 1940s with machines like Colossus.
Shifting between eras isn’t instant. We didn’t just turn off all the punched card machines one day and start using programmable computers. It was gradual, there was overlap – both in terms of there being a time when we were using both kinds of machine, but also in the way that some early programmable computers included elements of the types of systems that came before. We transitioned over time from one way of thinking about computers to another.

What was different about programmable computers was that you didn’t have to just give the data to a machine to process, you could also give it the instructions that you wanted it to carry out on that data.
When I think of early programmable computers, I think of the machines of the 1950s and 1960s. Huge machines that would fill a room.
But this is still the era we’re in today. Our computers today are faster, and smaller, and more powerful – and better in so many other ways. But fundamentally, architecturally, conceptually – our computers today work to the same principles of these early systems.

We think the third era of computing will be the era of cognitive machines. In the same way that the transition to programmable computers wasn’t instant, neither will this be. So it’s debatable whether we’re already in an era of cognitive machines, whether we’re starting to see early signs of it, or whether it’s something that we’re anticipating. Regardless of the exact date it starts, this is what we think will characterize the next generation of computers.
I should clarify what I mean by cognitive computing, because it’s perhaps not a term that has got mainstream awareness yet.
I’ve got a couple of examples to help me explain it.

What is 2+2?
If I give you the instruction or the question 2+2, what answer would you give me?

I assume that most of you would answer 4. Two plus two equals four.
That’s certainly the answer I’d expect from a programmable system – a system that has been hard-coded with instructions to follow, including instructions for how to handle adding numbers together.

But what if my question was in the context of social sciences, in a discussion about family structures. Then I probably would’ve been talking about the family structure of two adults and two children.

Or in the context of automotive engineering, I probably would’ve been talking about a layout of car seats with two front seats and two back seats.

Or in the context of card games, I might’ve meant a poker hand or a poker strategy.
The response I would’ve wanted will have been dependent on the context that my request was in. And this is the kind of behaviour that we would expect from a cognitive computer.
A programmable computer needs to be coded with the instructions to follow and the answer to return, and will always return that answer. Programmable computers are deterministic in this way. A calculator will always give me ‘4’, no matter how many times I ask 2+2.
Cognitive computers will be more probabilistic. They’ll likely return a panel of possible answers instead of a single answer, each one associated with some level of probability that it’s the right response. And this won’t be fixed, but will take the context of the question into account.

By context, I don’t just mean the situational context. It’s also about a knowledge of the things mentioned.
Consider this example, and what you think it means.
Policeman helps dog bite victim.

You’d probably assumes that this means that there is a dog bite victim.

And the policeman helps him.
Policeman helps dog bite victim.

You probably wouldn’t assume that it means that the policeman helped the dog to bite the victim.
But that’s a valid way to parse the sentence.
So that’s not all that you do – you use your knowledge of the things mentioned in the sentence to handle the ambiguity of the English language. You know that the police help people. You know it’d be unusual for a policeman to bite someone.
You use this knowledge to choose between the different possible interpretations of the sentence.
This is also the behaviour we’d expect from a cognitive computer.

Systems that interact with us in our own language. Instead of us having to use machine languages or machine interfaces to work with computers, we’ll work with cognitive computers in our own languages – languages like English.
Systems that are probabilistic rather than deterministic in the way they work and the answers that they return.
Systems that take context into account, and learn how to apply their knowledge to identify the most likely responses.

In 1997, an IBM computer beat the grandmaster Garry Kasparov at a game of chess. We did that as a demonstration of the progress that we’d made in a technical field (in that case, things like massively parallel computing) but also as a way of explaining it’s potential.
We did something similar to demonstrate and explain the progress that we’re making with cognitive computing, this time by entering a computer into a TV quiz show.
Jeopardy is a TV quiz show in the US – a few contestants, buzzing in when they know the answers to questions, and winning cash prizes. It’s less well-known in the UK, but it’s huge in the US – a show that’s been going since the 1960s.
They ask difficult questions. Complex, sometimes cryptic questions, with a variety of grammatical forms.

In 2011, we entered an IBM computer called Watson as a contestant. This was our first attempt at building a cognitive computer, and we wanted to show how it was different.

Watson went up against Brad Rutter and Ken Jennings – two of the best players to have ever gone on Jeopardy. These guys are household names in the US because of their performance on this show – these were the Garry Kasparov’s of the TV quiz show world.

Watson had to compete in the same way any contestant would. This wasn’t a search engine returning hundreds of thousands of possible documents. It needed to understand complex specific questions, and be able to come up with a single specific answer in seconds to be the first to the buzzer.

Some examples of the kinds of questions it got.
This was actually the final question in the show.
It’s talking about “Dracula” – the answer is Bram Stoker.

This is another Jeopardy question, from a round called “Lincoln Blogs”. The answer is “his resignation” – Chase submitted his resignation to President Abraham Lincoln three times.
But you need an understanding of the question, and the contextual knowledge that a resignation is something you submit, in order to get that.

This is a question about Mount Everest – about who was the first person to climb Mount Everest. But it doesn’t say that. It isn’t a single-clause extractive question like “Who was the first person to climb Mount Everest?” which would be much easier to interpret.
Again, answering this question precisely depends on knowing something about George Mallory and what he is known for, and knowing what kind of thing you might be “first” at in this context.

Another Jeopardy question, this time in a round called “Before and After”.
The answer it’s looking for is “A Hard Day’s Night of the Living Dead”
“A Hard Day’s Night” answering the Beatles bit, and “Night of the Living Dead” being the Romero zombie film.
“Before and After” is the clue that they’re looking for something with that overlap between them.

This question is showing it’s age now, given recent events in Cuba.
But at the time, I think the four countries that the US wasn’t getting along with were Bhutan, Cuba, North Korea and Iran. And the question is asking which of those four countries is furthest north.
Answering this question correctly involves needing to recognise that there is a political element here (which countries does the US not have diplomatic relations with) and then a spatial one (which one is furthest north).

By the end of the shows, Watson had not only won, but with a higher score than the two Jeopardy “grandmasters” combined.
Even within the limited constraints of the TV quiz show format, it gave us an insight into what the future might be like.
It showed what interaction with computers in the future will be like. Watson got the question from the quiz show host, understood it, buzzed in and spoke it’s answer.

The quiz show is just one way to try and explain this.
A more recent example is Chef Watson: a system that is learning about food and cooking, and using that to design new dishes and new meals.
You can give it some constraints, like that you’d like a chicken dish, or that you want something like a stir-fry, or that you’d like something influenced by a cuisine like Chinese. And you can tell it how adventurous and surprising you’d like it to be.
And it will design a new dish for you.

This isn’t about building a search engine for existing recipes.
Chefs from the ICE Culinary Institute are working with Watson to create new recipes.
They’ve trained it by giving it a massive amount of recipes to read. We didn’t manually prescribe types of dishes, types of cuisines and so on – we didn’t prescribe what characteristics we think an Indian dish for example would have. Instead, Watson had to learn that there is a type of cuisine like Caribbean and what that means as it came across a range of Caribbean recipes in what it’s read.

It was also given the chemical descriptions of a wide range of ingredients, and trained with a massive range of experiences of people’s reactions to specific flavour combinations.
Watson learned which combinations people liked, and which they didn’t – and identified connections and patterns in the molecular combinations behind that.
It’s about Watson as an assistant in the kitchen – making suggestions and offering ideas.
It’s helping us improve our understanding of creativity. It’s helping us improve our understanding of what is in involved in being creative (something that we traditionally associate with being a very human thing), and explore opportunities for cognitive computing to help with this.

We’ve used Chef Watson in the same way that we used the quiz show: to help explain the potential behind cognitive computing.
Putting Watson and the Chefs onto a food truck and taking them to conferences and events is a way of making it real. Letting people try the food that they come up with is one way to try and start a conversation how cognitive computing is going to be different.

Similarly, Watson has published a cook book of some of it’s recipes.
It’s kind of fun, and not something that I would’ve expected us to be doing a few years ago.
But we’re starting to find ways to explain cognitive computing through giving people tangible experiences.
Cognitive computing is still a very new and emerging concept, so it’s hard to find a definitive definition of what it means.
But I’ve collected a few examples of how it’s being described in technology, industry and academia.

Forrester have described it as computers that learn, computers that can interact with us, and computers that make evidence-based recommendations.

IBM has talked about the way cognitive systems will transform the way people will interact with computers, and highlighted that these systems will draw on knowledge from massive amounts of data.

Gartner, who describe this as the smart machines era, say that this is going to be most disruptive change in the history of IT, and talk about this enabling things that we didn’t think computers would be able to do.

MIT have talked about the collaborative nature of working with systems like these – like I tried to describe about Chef Watson, this is about systems working with people to create things that neither might have done separately.

The British Computer Society have talked about cognitive computing as systems that learn through experiences instead of following a prescribed sequence of tasks, and highlighted that these will handle massive amounts of information.

Sticking with this British Computer Society paper for a moment, they also highlight that there is a skills gap here.
For programmable systems, we need people who can understand what the overall task a machine needs to achieve, and can identify and describe the specific steps needed to do that.
Working with cognitive systems will be different. We need people who can identify the learning and experiential opportunities that a system will need in order to learn how to achieve the task.
There will be a need for a generation of technologists who can work with systems like this.

Preparing Watson for Jeopardy is a good example of this. We didn’t try to pre-empt what questions might come up on the show and pull together a set of answers to look them up in (not that I think such an approach would be feasible or scalable).
Instead, Watson prepared for Jeopardy by reading and extracting an understanding from a wide range of sources. I don’t mean game-show-specific sources. I don’t mean tabular data, or structured data, or data that has been manually prepared to be machine readable. I’m talking about encyclopaedias and dictionaries, newspapers and magazines, books and much more. Hundreds of sources of text – stuff that has been written for use by people.

And it learned how to use this knowledge by playing Jeopardy matches. Lots and lots of Jeopardy matches, to give it the experiences it needs to learn how to use it’s knowledge, and when to use it’s many hundreds of strategies it has under the covers. Some questions are best handled in these ways, while other questions are better handled in other ways.
Watson learned how by playing the game, and got better through sparring matches with other previous champions from the Jeopardy TV show.

Since the TV show in 2011, a big focus for our work with Watson has been healthcare.
Jeopardy was about taking a wide range of general knowledge sources, letting Watson extract a knowledge from that, and then giving it the experiences necessary to learn how to use that knowledge to do the task of playing a gameshow.
After Jeopardy, we started giving Watson medical sources – text books, journals, research papers, treatment guidelines, medical records, and then working with doctors and clinicians to give Watson the experiences necessary to use that knowledge to support doctors and nurses.

We’ve partnered with cancer centres like Memorial Sloan Kettering and MD Anderson to do this. What we need are partners who understand what the system will need to be able to do, and can work backwards from there to identify what knowledge it will need and what experiences the system will need to have in order to use that knowledge to do it.
In many ways, teaching hospitals are ideal partners for us in this because they do this for their medical students. And the metaphor of Watson going to medical school is one that seems to have stuck. It’s not quick – it’s taking a roughly comparable amount of time that it would take a person to go through medical school.
But it’s working. Watson is being used today, albeit at relatively small scales, by doctors and nurses in the treatment and diagnosis of some of the world’s toughest diseases.

It doesn’t have to be so dramatic though. I think cognitive computing will become a part of all of our lives, not just something exclusive to specialists like doctors.
I went to a conference in Twickenham last year, and one of the talks was about a project for a mobile phone retailer, trialling cognitive computing as a way to answer the questions they get from their customers.
I loved the way that he described what they’re doing – working with Watson, rather than using it. And he described it as being like having a new member of staff to train, and needing to identify what that new member of staff would need to read, and what experiences of customer interactions they could give it to teach it how to support them.

Examples of this are all around us. In the same way that the early programmable systems built on the achievements and techniques that had come before them, cognitive computers are building on years of progress in fields like machine learning and natural language processing.
Google Translate is a great example of this.
You put in some text in one language, and it can translate that into another.
Unlike many of the translation systems that came before it, they didn’t build this just by collecting together linguists and getting them to prescribe the instructions for translating every word.
Instead, they trained a machine learning system to be able to do this, using sources like documents from the United Nations. The UN is a great source for this as they produce a lot of documents, and have to translate them into a wide range of languages for all their member nations.
What you’ve got is a large number of examples that this in one language means that in another.
Cognitive computing will need us to approach problems in this way – not trying to come up with all the answers ourselves, but being able to identify how to give a computer the experiences it will need in order to help.

I said that there is going to be a skills gap here, and we’re already starting to see it in the graduates that join us.
We’re starting to tackle that by working with Universities to introduce modules on cognitive computing into their courses, and giving them access to instances of Watson for use in student projects.
But there will come a point where we need to start introducing it earlier, into colleges and schools.

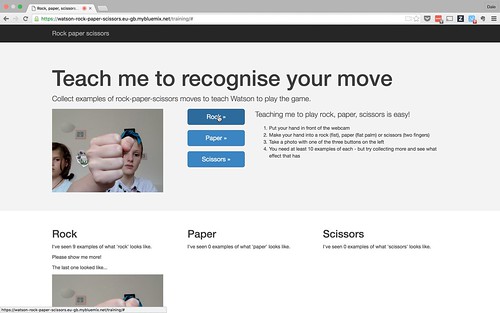
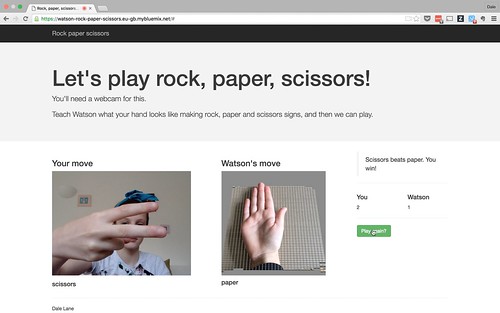
We need to start thinking about how we explain the computers of the future to children.
We need to think about what is the cognitive computing equivalent of Big Trak.
That experience made computers real to me as a kid. It inspired me. It made the concept and the potential come alive. What is going to do that for cognitive computers?

In the same way that systems like Logo and Scratch have given us the way to let children try out and play with the concepts behind programmable computers, we need a way to do this for cognitive systems.
Scratch has it’s palette of blocks to snap together. What is going to be the metaphor to explain systems that need to trained?

We talk about computers that can think. It’s obviously a metaphor, and is true in many ways but doesn’t hold in others. I’m not trying to imply I think these are going to be systems with a conciousness any time soon.
But how far can we take the metaphor? As we need people who can work with systems that think and learn, this needs to take into account the way that computers learn.
At the risk of pushing the metaphor too far, we need an approach built around the psychology of these emerging systems.

I started by saying that big changes are coming in computing. Tomorrow’s children are going to have amazing, exciting, powerful systems to play with, and they’re going to grow up and use them to achieve fantastic things.
But first we’re going to need to figure out how to get them started.