
Executive Summary
When a mummy function node and a daddy function node love each other very much, the daddy node injects a payload into the mummy node through a wire between them, and a new baby message flow is made, which comes out of mummy’s output terminal. The baby’s name is Jason.
Where did this idea come from?
In Node-RED, if you export some nodes to the clipboard, you will see the flow and its connections use a JSON wire format.
For a few weeks I’ve been thinking about generating that JSON programmatically, in order to create flows which encode various input and output capabilities and functions, according to some input parameters which give the specific details of what the flow is to do.
I think there’s been an alignment of planets that’s occurred, which led to this idea:
@stef_k_uk has been talking to me about deploying applications onto “slave” Raspberry Pis from a master Pi.
Dritan Kaleshi and Terence Song from Bristol University have been discussing using the Node-RED GUI as a configurator tool for a system we’re working on together, and also we’ve been working on representing HyperCat catalogues in Node-RED, as part of our Technology Strategy Board Internet of Things project, IoT-Bay.
@rocketengines and I were cooking up cool ideas for cross-compiling Node-RED flows into other languages, a while back, and
in a very productive ideas afternoon last week, @profechem and I stumbled upon an idea for carrying the parser for a data stream along with the data itself, as part of its meta-data description.
All of the above led me to think “wouldn’t it be cool if you could write a flow in Node-RED which produced as output another flow.” And for this week’s #ThinkFriday afternoon, I gave it a try.
First experiment
The first experiment was a flow which had an injector node feeding a JSON object of parameters into a flow which generated the JSON for an MQTT input node, a function node to process the incoming data in some way, and an MQTT output node. So it was the classic subscribe – process – publish pattern which occurs so often in our everday lives (if you live the kind of life that I do!).
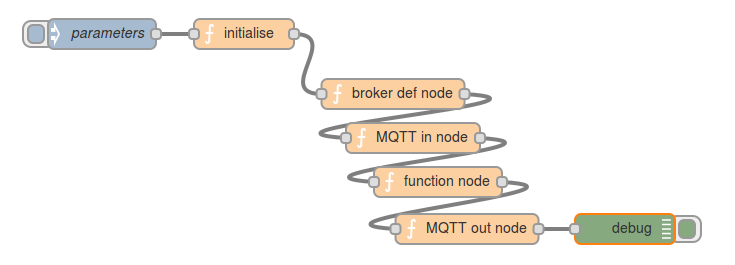 And here’s the Node-RED flow which generates that: flow-generator
And here’s the Node-RED flow which generates that: flow-generator
So if you sent in
{
"broker": "localhost",
"input": "source_topic",
"output": "destination_topic",
"process": "msg.payload = \"* \"+msg.payload+\" *\";\nreturn msg;"
}
the resulting JSON would be the wire format for a three-node flow which has an MQTT input node subscribed to “source_topic” on the broker on “localhost”, a function node which applies a transformation to the data: in this case, wrapping it with an asterisk at each end, and finally an MQTT publish node sending it to “destination_topic” on “localhost”.
N.B. make sure you escape any double quotes in the “process” string, as shown above.
The JSON appears in the debug window. If you highlight it, right-mouse – Copy, and then do Import from… Clipboard in Node-RED and ctrl-V the JSON into the text box and click OK, you get the three node flow described above ready to park on your Node-RED worksheet and then Deploy.
 And it works!!
And it works!!
So what?
So far so cool. But what can we do with it?
The next insight was that the configuration message (supplied by the injector) could come from somewhere else. An MQTT topic, for example. So now we have the ability for a data stream to be accompanied not only by meta-data describing what it is, but also have the code which parses it.
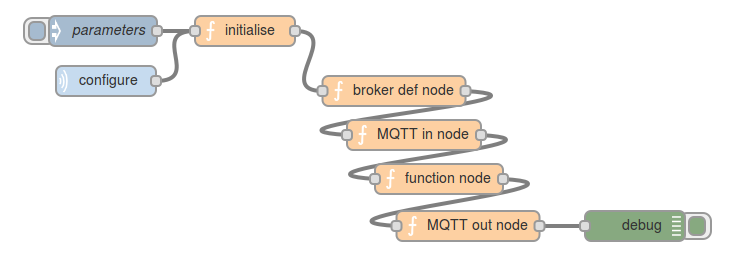 My thinking is that if you subscribe to a data topic, say:
My thinking is that if you subscribe to a data topic, say:
andy/house/kitchen/temperature
there could be two additional topics, published “retained” so you get them when you first subscribe, and then any updates thereafter:
A metadata topic which describes, in human and/or machine readable form, what the data is about, for example:
andy/house/kitchen/temperature/meta with content
“temperature in degrees Celcius in the kitchen at Andy’s house”
And a parser topic which contains the code which enables the data to be parsed:
andy/house/kitchen/temperature/parser with content
“msg.value = Math.round(msg.payload) + \" C\"; return msg;”
(that’s probably a rubbish example of a useful parser, but it’s just for illustration!)
If you’re storing your data in a HyperCat metadata catalogue (and you should think about doing so if you’re not – see @pilgrimbeart‘s excellent HyperCat in 15 minutes presentation), then the catalogue entry for the data point could include the URI of the parser function along with the other meta-data.
And then…
Now things get really interesting… what if we could deploy that flow we’ve created to a node.js run-time and set it running, as if we’d created the flow by hand in the Node-RED GUI and clicked “Deploy”?
Well we can!
When you click Deploy, the Node-RED GUI does an HTTP POST to “/flows” in the node.js run-time that’s running the Node-RED server (red.js), and sends it the list of JSON objects which describe the flow that you’ve made.
So… if we hang an HTTP request node off the end of the flow which generates the JSON for our little flow, then it should look like a Deploy from a GUI.
Et voila!
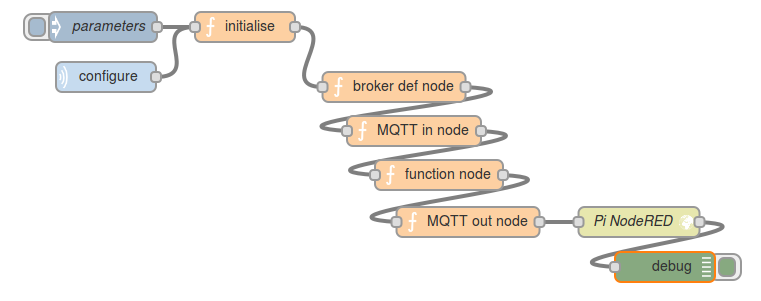
Note that you have to be careful not to nuke your flow-generating-flow by posting to your own Node-RED run-time! I am posting the JSON to Node-RED on my nearby Raspberry Pi. When you publish a configuration message to the configuration topic of this flow, the appropriate set of nodes is created – input – process – output – and then deployed to Node-RED on the Pi, which dutifully starts running the flow, subscribing to the specified topic, transforming the data according to the prescribed processing function, and publishing it to the specified output topic.
I have to say, I think this is all rather exciting!
Footnote:
It’s worth mentioning, that Node-RED generates unique IDs for nodes that look like “8cf45583.109bf8”. I’m not sure how it does that, so I went for a simple monotonically increasing number instead (1, 2 …). It seems to work fine, but there might be good reasons (which I’m sure @knolleary will tell me about) why I should do it the “proper” way.