
After Monkigras 2013, I was really looking forward to Monkigras 2014. The great talks about developer culture and creating usable software, the amazing buzz and friendliness of the event, the wonderful lack of choice over which talks to go to (there’s just one track!!), and (of course) the catering:


The talks at Monkigras 2014
The talks were pretty much all great so I’m just going to mention the talks that were particularly relevant to me.
Rafe Colburn from Etsy talked about how to motivate developers to fix bugs (IBMers, read ‘defects’) when there’s a big backlog of bugs to fix. They’d tried many strategies, including bug rotation, but none worked. The answer, they found, was to ask their support team to help prioritise the bugs based on the problems that users actually cared about. That way, the developers fixing the bugs weren’t overwhelmed by the sheer numbers to choose from. Also, when they’d done a fix, the developers could feel that they’d made a difference to the user experience of the software.

While I’m not responsible for motivating developers to fix bugs, my job does involve persuading developers to write articles or sample code for WASdev.net. So I figure I could learn a few tricks.
A couple of talks that were directly applicable to me were Steve Pousty‘s talk on how to be a developer evangelist and Dawn Foster‘s on taking lessons on community from science fiction. The latter was a quick look through various science fiction themes and novels applied to developer communities, which was a neat idea though I wished I’d read more of the novels she cited. I was particularly interested in Steve’s talk because I’d seen him speak last year about how his PhD in Ecology had helped him understand communities as ecosystems in which there are sometimes surprising dependencies. This year, he ran through a checklist of attributes to look for when hiring a developer evangelist. Although I’m not strictly a developer evangelist, there’s enough overlap with my role to make me pay attention and check myself against each one.

One of the risks of TED Talk-style talks is that if you don’t quite match up to the ‘right answers’ espoused by the speakers, you could come away from the event feeling inadequate. The friendly atmosphere of Monkigras, and the fact that some speakers directly contradicted each other, meant that this was unlikely to happen.
It was still refreshing, however, to listen to Theo Schlossnagle basically telling people to do what they find works in their context. Companies are different and different things work for different companies. Similarly, developers are people and people learn in different ways so developers learn in different ways. He focused on how to tell stories about your own failures to help people learn and to save them from having to make the same mistakes.
Again, this was refreshing to hear because speakers often tell you how you should do something and how it worked for them. They skim over the things that went wrong and end up convincing you that if only you immediately start doing things their way, you’ll have instant success. Or that inadequacy just kicks in like when you read certain people’s Facebook statuses. Theo’s point was that it’s far more useful from a learning perspective to hear about the things that went wrong for them. Not in a morbid, defeatist way (that way lies only self-pity and fear) but as a story in which things go wrong but are righted by the end. I liked that.

Ana Nelson (geek conference buddy and friend) also talked about storytelling. Her point was more about telling the right story well so that people believe it rather than believing lies, which are often much more intuitive and fun to believe. She impressively wove together an argument built on various fields of research including Psychology, Philosophy, and Statistics. In a nutshell, the kind of simplistic headlines newspapers often publish are much more intuitive and attractive because they fit in with our existing beliefs more easily than the usually more complicated story behind the headlines.

The Gentle Author spoke just before lunch about his daily blog in which he documents stories from local people. I was lucky enough to win one of his signed books, which is beautiful and engrossing. Here it is with my swagbag:
My swag bag from #monkigras – I was a lucky recipient of a beautiful, signed London Album by @thegentleauthor pic.twitter.com/6BaqBdtXP5
— Laura Cowen (@lauracowen) February 1, 2014
After his popular talk last year, Phil Gilbert of IBM returned to give an update on how things are going with Design@IBM. Theo’s point about context of a company being important is so relevant when trying to change the culture of such a large company. He introduced a new card game that you can use to help teach people what it’s like to be a designer working within the constraints of a real software project. I heard a fair amount of interest from non-IBMers who were keen for a copy of the cards to be made available outside IBM.

On the UX theme, I loved Leisa Reichelt‘s talk about introducing user research to the development teams at GDS. While all areas of UX can struggle to get taken seriously, user research (eg interviewing participants and usability testing) is often overlooked because it doesn’t produce visual designs or code. Leisa’s talk was wonderfully practical in how she related her experiences at GDS of proving the worth of user research to the extent that the number of user researchers has greatly increased.
And lastly I must mention Project Andiamo, which was born at Monkigras 2013 after watching a talk about laser scanning and 3D printing old railway trains. The project aims to produce medical orthotics, like splints and braces, by laser scanning the patient’s body and then 3D printing the part. This not only makes the whole process much quicker and more comfortable, it is at a fraction of the cost of the way that orthotics are currently made.

If you can help in any way, take a look at their website and get in touch with them. Samiya and Naveed’s talk was an amazing example of how a well-constructed story can get a powerful message across to its listeners:
"This is supposed to be a compliment, but your talk made me cry" – @monkigras
— Charlotte Spencer (@Charlotteis) January 31, 2014
After Monkigras 2014, I’m now really looking forward to Monkigras 2015.
My 11yr old just said that #monkigras could be translated as "fat monkey" … not sure what to make of that @monkchips
— Paul Johnston (@PaulDJohnston) February 12, 2014
The post Monkigras 2014: Sharing craft appeared first on LauraCowen.co.uk.








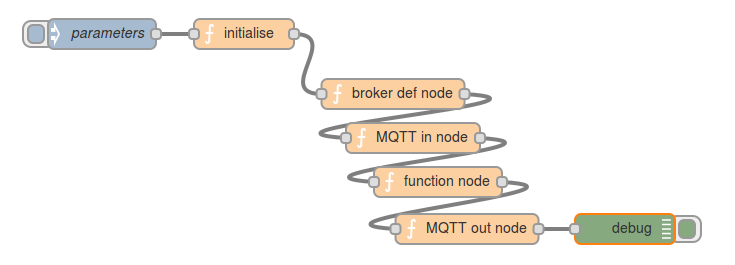 And here’s the Node-RED flow which generates that:
And here’s the Node-RED flow which generates that:  And it works!!
And it works!!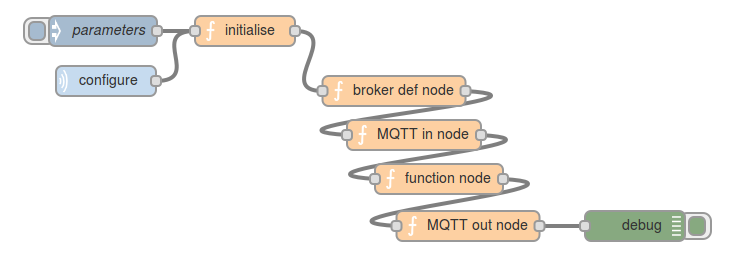 My thinking is that if you subscribe to a data topic, say:
My thinking is that if you subscribe to a data topic, say: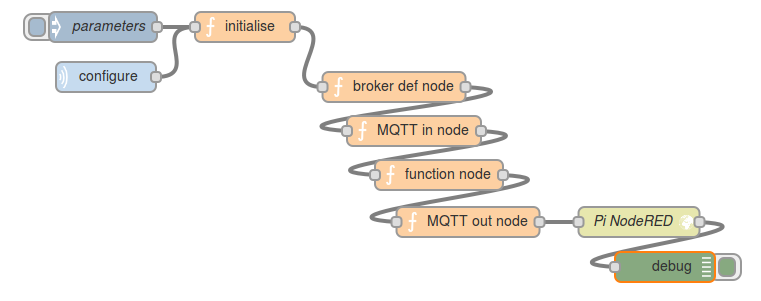




 Matt Webb
Matt Webb Patrick Bergel
Patrick Bergel The talk which chimed the most with me, though, was
The talk which chimed the most with me, though, was 





















